不知道你有沒有發現,之前的爬蟲實作找到的資料都是只有第一頁的,不會抓到第二頁的資料,今天要介紹另一個爬蟲常用工具--Selenium,它是模擬一般人瀏覽網頁的所有習性,缺點是速度會比較慢,很仰賴網速也會消耗大量CPU,但是但是,它絕對是資料科學領域不可不學的爬蟲工具!
要用這個工具必須要使用到瀏覽器,所以不能使用線上環境,需要用本地的環境寫,這點要注意一下~另外需要有指令介面driver,這個介面跟python是無關的,你可以選擇你常用的瀏覽器,這部分我是選擇Chrome,可以到這裡下載,記得要檢查目前的瀏覽器版本,再下載對應的WebDriver,在正式開始coding前也要記得把ChromeDriver拖曳到當前程式的資料夾,第三個必須的工具就是要下載Selenium套件。
開啟瀏覽器後點選右上的三個點點,選擇「說明」裡的「關於Google Chrome」,一進去就會顯示你目前的版本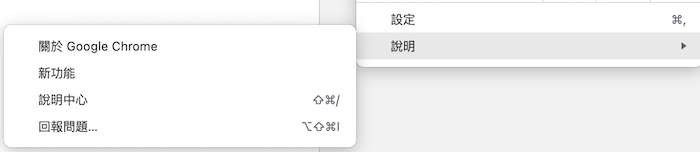
像我是105.0.5195.125 (正式版本) (arm64)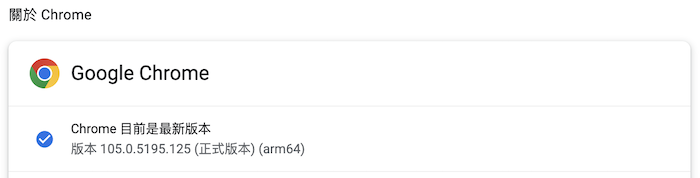
進到官網後選擇版本,我是選擇105版,再根據你的作業系統選擇檔案。下載完記得要拖曳到目前的程式資料夾~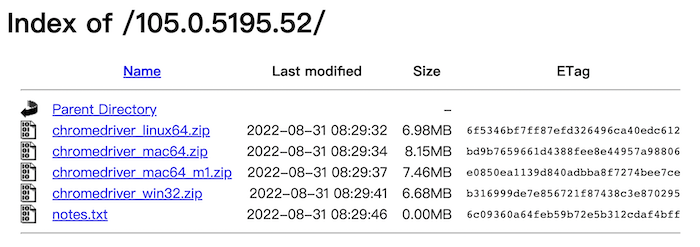
from selenium.webdriver import Chrome # 引入driver
driver = Chrome("./chromedriver")
driver.get("https://www.google.com") # 輸入網址
driver.maximize_window() # 視窗最大化
第一次執行你可能會遇到系統顯示無法打開「chromedriver」,因為Apple無法檢查是否包含惡意軟體,這時候莫急莫慌莫害怕,只要回到資料夾雙擊打開檔案,接下來就一路順暢ㄌ!
剛剛把前置作業做完後,接下來就要開始模擬一般人瀏覽網頁的行為。現在回想一下自己在google頁面上搜尋關鍵字時,都是如何進行的?是不是先打開瀏覽器在網址列輸入google網址,等頁面出現後再將把想查詢的關鍵字輸入到搜尋框裡。所以如果要透過Python來模擬這樣子的行為,首先需要對元素進行「定位」,才可以繼續操作網頁的其他行為。
定位其實也很簡單,之前也做過無數次了,打開F12,選擇方塊箭頭移到想查詢的區域就會顯示那部份的程式碼,接著要利用程式找到這部分程式碼,之前在BeautifulSoup時是使用find或是find_all,selenium其實也很像,只是分別換成了find_element及find_elements,括號內寫入目標區域的class名稱,並使用send_keys輸入關鍵字。
題外話,最近好忙再加上睡不好,黑眼圈重到讓我看起來就像被打過,嗚嗚嗚我要開始尋找好用的遮瑕
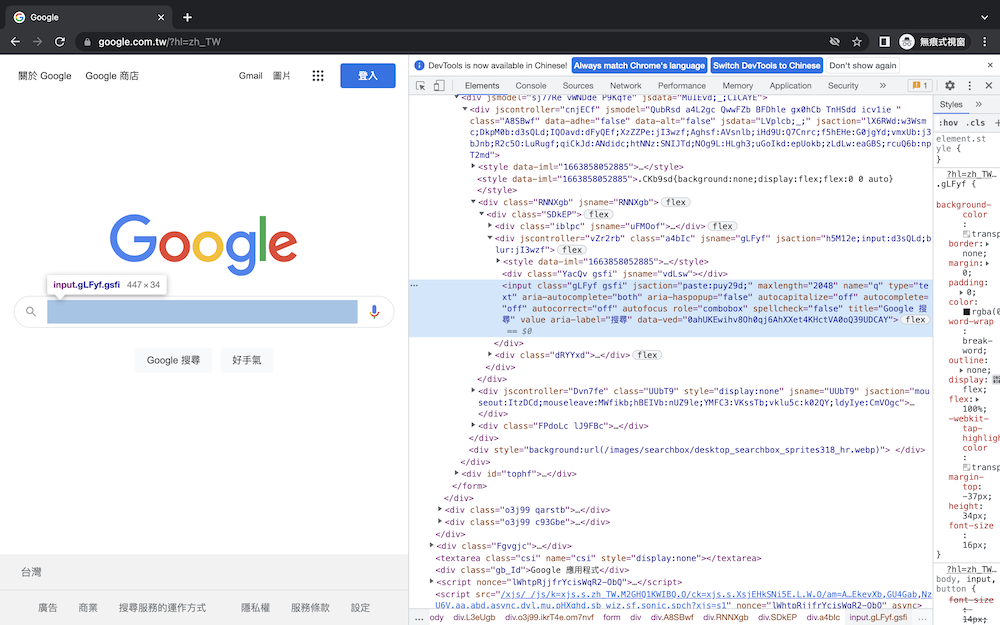
from selenium.webdriver.common.by import By
from selenium.webdriver import Chrome
driver = Chrome("./chromedriver")
driver.get("https://www.google.com")
driver.maximize_window()
element = driver.find_element(By.CLASS_NAME, "gLFyf").send_keys("遮瑕") # 定位搜尋框並輸入關鍵字
但目前只是輸入關鍵字而已,沒有按下Enter怎麼搜尋勒,所以要修改一下,使用到Keys,不過這部分就要再import另一個方法。
from selenium.webdriver.common.keys import Keys
element = driver.find_element(By.CLASS_NAME, "gLFyf")
element.send_keys("遮瑕")
element.send_keys(Keys.ENTER)
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver import Chrome
driver = Chrome("./chromedriver")
driver.get("https://www.google.com")
driver.maximize_window()
element = driver.find_element(By.CLASS_NAME, "gLFyf")
element.send_keys("遮瑕")
element.send_keys(Keys.ENTER)
好啦今天就先到這裡,我要去睡美容覺啦,祝大家每天都可以有個好夢~

